一、什么是memcache
MemCache是一个自由、源码开放、高性能、分布式的分布式内存对象缓存系统,
MemCaChe是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)使用key-value存储,数据可以来自数据库调用、API调用,或者页面渲染的结果。
MemCache设计理念就是小而强大,它简单的设计促进了快速部署、易于开发并解决面对大规模的数据缓存的许多难题
同类产品:Redis
二、为什么要使用memcache
主要用于动态Web应用以减轻数据库的负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度。
由于网站的高并发读写需求,传统的关系型数据库开始出现瓶颈,例如:
1)对数据库的高并发读写: 关系型数据库本身就是个庞然大物,处理过程非常耗时(如解析SQL语句,事务处理等)。如果对关系型数据库进行高并发读写(每秒上万次的访问),那么它是无法承受的。
2)对海量数据的处理: 对于大型的SNS网站,每天有上千万次的数据产生(如twitter, 新浪微博)。对于关系型数据库,如果在一个有上亿条数据的数据表种查找某条记录,效率将非常低。
三、memcache的组成部分与实现原理
memcache有两个核心组件:服务端和客户端
memcache处理的原子是每一个key、val,key会通过一个hash表转换成hash的key,便于查找对比以及竟可能的做到散列。同时mem用的是一个二级散列,通过一个hash表来维护。
在一个memcache组件查询中,client先通过key的hash值来确定kv在service端的位置,当server端确定后,客户端就会发一个请求个server端。让它来查找出确切数据,因为这之间没有交互以及多播协议,因此mem带给网络的影响最小
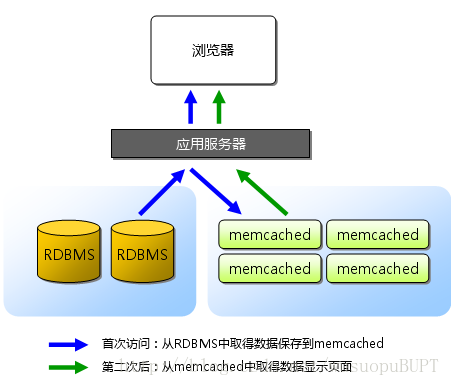
工作过程:
1.检查用户请求的数据是缓存中是否有存在,如果有存在的话,只需要直接把请求的数据返回,无需查询数据库。
2.如果请求的数据在缓存中找不到,这时候再去查询数据库。返回请求数据的同时,把数据存储到缓存中一份。
3.保持缓存的“新鲜性”,每当数据发生变化的时候(比如,数据有被修改,或被删除的情况下),要同步的更新缓存信息,确保用户不会在缓存取到旧的数据。
四、MemCache和MemCached的区别
1、MemCache是项目的名称 2、MemCached是MemCache服务器端可以执行文件的名称